class: center, middle, inverse, title-slide # Quantifying lexical contact in Daghestan ### M. Daniel, I. Chechuro, S. Verhees ### 20.02.2018 <br> Linguistic Convergence Lab seminar --- ## Outline of the talk - Comparison of our shortlist and the WOLD questionnaire -- - Data from the field: Rutul region + Similarity sets and distance matrices + Neighbournet visualization -- - Dictionary data: neighbournet -- - Avar area -- - Further plans --- ## World Loanword Database project: a brief overview - [WOLD](http://wold.clld.org/meaning) questionnaire - 1814 items -- - The aim of the [WOLD](http://wold.clld.org/meaning) project: empirical test of lexical borrowability -- - East Caucasian in [WOLD](http://wold.clld.org/meaning): two languages in central Daghestan: Archi (Lezgic) and Bezhta (Tsezic) -- - [WOLD](http://wold.clld.org/meaning) includes all parts of speech (including 905 nouns, 334 verbs, 120 adjectives ...) -- - Empirically confirms the lexical borrowability hierarchy, with the Noun on top -- - Conclusion: to easily quantify lexical contact, focus on nouns --- ## Shortlist - We decided to also compile a short list that can be quickly collected in the field from several speakers - WOLD is too long -- - The short list was supposed to show a high ratio of horyzontally borrowed items (higher than full WOLD), lower ratio of vertical borrowings -- - Thus: nouns coming from mid-range of the WOLD list (from 30 to 45) - to avoid conservative lexical items and lexical items typical in vertical borrowings; names of locally non-existent objects were avoided; some assumedly locally important nouns were added -- - Resulting shortlist: some 225 nouns --- ## Shortlist versus WOLD longlist <table> <thead> <tr> <th style="text-align:left;"> Archi </th> <th style="text-align:right;"> WOLD </th> <th style="text-align:right;"> % </th> <th style="text-align:right;"> short </th> <th style="text-align:right;"> % </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> Horizontal </td> <td style="text-align:right;"> 100 </td> <td style="text-align:right;"> 8 </td> <td style="text-align:right;"> 17 </td> <td style="text-align:right;"> 8 </td> </tr> <tr> <td style="text-align:left;"> Avar </td> <td style="text-align:right;"> 77 </td> <td style="text-align:right;"> 6 </td> <td style="text-align:right;"> 13 </td> <td style="text-align:right;"> 6 </td> </tr> <tr> <td style="text-align:left;"> Lak </td> <td style="text-align:right;"> 23 </td> <td style="text-align:right;"> 2 </td> <td style="text-align:right;"> 4 </td> <td style="text-align:right;"> 2 </td> </tr> <tr> <td style="text-align:left;"> Turkic </td> <td style="text-align:right;"> 22 </td> <td style="text-align:right;"> 2 </td> <td style="text-align:right;"> 9 </td> <td style="text-align:right;"> 4 </td> </tr> <tr> <td style="text-align:left;"> Vertical </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 12 </td> <td style="text-align:right;"> 0 </td> <td style="text-align:right;"> 17 </td> </tr> <tr> <td style="text-align:left;"> Arabic </td> <td style="text-align:right;"> 64 </td> <td style="text-align:right;"> 5 </td> <td style="text-align:right;"> 10 </td> <td style="text-align:right;"> 5 </td> </tr> <tr> <td style="text-align:left;"> Persian </td> <td style="text-align:right;"> 31 </td> <td style="text-align:right;"> 2 </td> <td style="text-align:right;"> 15 </td> <td style="text-align:right;"> 7 </td> </tr> <tr> <td style="text-align:left;"> Russian </td> <td style="text-align:right;"> 59 </td> <td style="text-align:right;"> 5 </td> <td style="text-align:right;"> 10 </td> <td style="text-align:right;"> 5 </td> </tr> <tr> <td style="text-align:left;"> Unidentified </td> <td style="text-align:right;"> 197 </td> <td style="text-align:right;"> 16 </td> <td style="text-align:right;"> 59 </td> <td style="text-align:right;"> 28 </td> </tr> <tr> <td style="text-align:left;"> Non loan </td> <td style="text-align:right;"> 781 </td> <td style="text-align:right;"> 62 </td> <td style="text-align:right;"> 92 </td> <td style="text-align:right;"> 43 </td> </tr> <tr> <td style="text-align:left;"> NA </td> <td style="text-align:right;"> 310 </td> <td style="text-align:right;"> 25 </td> <td style="text-align:right;"> 39 </td> <td style="text-align:right;"> 18 </td> </tr> <tr> <td style="text-align:left;"> Total without NA </td> <td style="text-align:right;"> 1254 </td> <td style="text-align:right;"> 100 </td> <td style="text-align:right;"> 212 </td> <td style="text-align:right;"> 100 </td> </tr> </tbody> </table> --- ## Shortlist versus WOLD longlist <table> <thead> <tr> <th style="text-align:left;"> Bezhta </th> <th style="text-align:right;"> WOLD </th> <th style="text-align:right;"> % </th> <th style="text-align:right;"> short </th> <th style="text-align:right;"> % </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> Horizontal </td> <td style="text-align:right;"> 219 </td> <td style="text-align:right;"> 15 </td> <td style="text-align:right;"> 59 </td> <td style="text-align:right;"> 24 </td> </tr> <tr> <td style="text-align:left;"> Avar </td> <td style="text-align:right;"> 156 </td> <td style="text-align:right;"> 11 </td> <td style="text-align:right;"> 30 </td> <td style="text-align:right;"> 12 </td> </tr> <tr> <td style="text-align:left;"> Georgian </td> <td style="text-align:right;"> 63 </td> <td style="text-align:right;"> 4 </td> <td style="text-align:right;"> 29 </td> <td style="text-align:right;"> 12 </td> </tr> <tr> <td style="text-align:left;"> Turkic </td> <td style="text-align:right;"> 20 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 9 </td> <td style="text-align:right;"> 4 </td> </tr> <tr> <td style="text-align:left;"> Vertical </td> <td style="text-align:right;"> 218 </td> <td style="text-align:right;"> 15 </td> <td style="text-align:right;"> 47 </td> <td style="text-align:right;"> 19 </td> </tr> <tr> <td style="text-align:left;"> Arabic </td> <td style="text-align:right;"> 79 </td> <td style="text-align:right;"> 5 </td> <td style="text-align:right;"> 12 </td> <td style="text-align:right;"> 5 </td> </tr> <tr> <td style="text-align:left;"> Persian </td> <td style="text-align:right;"> 27 </td> <td style="text-align:right;"> 2 </td> <td style="text-align:right;"> 12 </td> <td style="text-align:right;"> 5 </td> </tr> <tr> <td style="text-align:left;"> Russian </td> <td style="text-align:right;"> 112 </td> <td style="text-align:right;"> 8 </td> <td style="text-align:right;"> 23 </td> <td style="text-align:right;"> 9 </td> </tr> <tr> <td style="text-align:left;"> Unidentified </td> <td style="text-align:right;"> 13 </td> <td style="text-align:right;"> 1 </td> <td style="text-align:right;"> 7 </td> <td style="text-align:right;"> 3 </td> </tr> <tr> <td style="text-align:left;"> Non loan </td> <td style="text-align:right;"> 999 </td> <td style="text-align:right;"> 68 </td> <td style="text-align:right;"> 123 </td> <td style="text-align:right;"> 50 </td> </tr> <tr> <td style="text-align:left;"> NA </td> <td style="text-align:right;"> 95 </td> <td style="text-align:right;"> 6 </td> <td style="text-align:right;"> 6 </td> <td style="text-align:right;"> 2 </td> </tr> <tr> <td style="text-align:left;"> Total without NA </td> <td style="text-align:right;"> 1469 </td> <td style="text-align:right;"> 100 </td> <td style="text-align:right;"> 245 </td> <td style="text-align:right;"> 100 </td> </tr> </tbody> </table> --- ## Shortlist versus WOLD longlist - The shortlist does not increase the percentage of horyzontal loans; neither does it reduce the percentage of vertical loans - instead, it captures percentages similar to the long list -- - For Archi, they concur with data on multilingualism (many people speak Avar, some speak Lak) -- - Relative rise of Georgian borrowings in Bezhta seems to be due to the domain of everyday objects (e.g. 'spoon', 'candle'). --- class: inverse, center, middle ## The rationale for the fieldwork - Even for minority languages, dictionaries tend to be on the conservative (pure language) side -- - Collect more naturalistic data on the usage of loanwords from speakers -- - Collect comparable data from several speakers in a partly controlled experimental setting -- - Downs: no strict transcription of the data, similarity judgements without etymological investigation --- ## Fieldwork <div id="htmlwidget-a2513d605a4c3a8e2f01" style="width:748.8px;height:504px;" class="leaflet html-widget"></div> <script type="application/json" data-for="htmlwidget-a2513d605a4c3a8e2f01">{"x":{"options":{"crs":{"crsClass":"L.CRS.EPSG3857","code":null,"proj4def":null,"projectedBounds":null,"options":{}},"zoomControl":true},"calls":[{"method":"addTiles","args":["Esri.OceanBasemap",null,null,{"minZoom":0,"maxZoom":18,"maxNativeZoom":null,"tileSize":256,"subdomains":"abc","errorTileUrl":"","tms":false,"continuousWorld":false,"noWrap":false,"zoomOffset":0,"zoomReverse":false,"opacity":1,"zIndex":null,"unloadInvisibleTiles":null,"updateWhenIdle":null,"detectRetina":false,"reuseTiles":false}]},{"method":"addProviderTiles","args":["Esri.OceanBasemap",null,"Esri.OceanBasemap",{"errorTileUrl":"","noWrap":false,"zIndex":null,"unloadInvisibleTiles":null,"updateWhenIdle":null,"detectRetina":false,"reuseTiles":false}]},{"method":"addCircleMarkers","args":[[42.7856,42.800361,42.731394,42.782304,41.781293,42.1339,42.667813,42.1764,41.496274,41.693931,41.6166,41.53146,41.5342,41.62466,42.1931],[46.2639,46.292645,46.319223,46.319372,46.949207,46.1247,46.221451,45.98646,47.533824,47.210005,47.2647,47.48171,47.4269,47.17889,45.9583],5.5,null,["Andi","Andi","Andi","Andi","Avar","Bezhta","Botlikh","Hinuq","Lezgian","Rutul","Rutul","Rutul","Rutul","Tsakhur","Tsez"],{"lineCap":null,"lineJoin":null,"clickable":true,"pointerEvents":null,"className":"","stroke":false,"color":"black","weight":5,"opacity":0.5,"fill":true,"fillColor":"black","fillOpacity":1,"dashArray":null},null,null,["<a href='http://glottolog.org/resource/languoid/iso/ani' target='_blank'>Andi<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/ani' target='_blank'>Andi<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/ani' target='_blank'>Andi<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/ani' target='_blank'>Andi<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/ava' target='_blank'>Avar<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/kap' target='_blank'>Bezhta<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/bph' target='_blank'>Botlikh<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/gin' target='_blank'>Hinuq<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/lez' target='_blank'>Lezgian<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/rut' target='_blank'>Rutul<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/rut' target='_blank'>Rutul<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/rut' target='_blank'>Rutul<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/rut' target='_blank'>Rutul<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/tkr' target='_blank'>Tsakhur<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/ddo' target='_blank'>Tsez<\/a><br>"],null,null,null,null]},{"method":"addCircleMarkers","args":[[42.7856,42.800361,42.731394,42.782304,41.781293,42.1339,42.667813,42.1764,41.496274,41.693931,41.6166,41.53146,41.5342,41.62466,42.1931],[46.2639,46.292645,46.319223,46.319372,46.949207,46.1247,46.221451,45.98646,47.533824,47.210005,47.2647,47.48171,47.4269,47.17889,45.9583],5,null,["Andi","Andi","Andi","Andi","Avar","Bezhta","Botlikh","Hinuq","Lezgian","Rutul","Rutul","Rutul","Rutul","Tsakhur","Tsez"],{"lineCap":null,"lineJoin":null,"clickable":true,"pointerEvents":null,"className":"","stroke":false,"color":["#CD8500","#CD8500","#CD8500","#CD8500","#FFFF00","#DB7093","#F4A460","#FFC0CB","#74C476","#ADFF2F","#ADFF2F","#ADFF2F","#ADFF2F","#2E8B57","#FF4040"],"weight":5,"opacity":0.5,"fill":true,"fillColor":["#CD8500","#CD8500","#CD8500","#CD8500","#FFFF00","#DB7093","#F4A460","#FFC0CB","#74C476","#ADFF2F","#ADFF2F","#ADFF2F","#ADFF2F","#2E8B57","#FF4040"],"fillOpacity":1,"dashArray":null},null,null,["<a href='http://glottolog.org/resource/languoid/iso/ani' target='_blank'>Andi<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/ani' target='_blank'>Andi<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/ani' target='_blank'>Andi<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/ani' target='_blank'>Andi<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/ava' target='_blank'>Avar<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/kap' target='_blank'>Bezhta<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/bph' target='_blank'>Botlikh<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/gin' target='_blank'>Hinuq<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/lez' target='_blank'>Lezgian<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/rut' target='_blank'>Rutul<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/rut' target='_blank'>Rutul<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/rut' target='_blank'>Rutul<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/rut' target='_blank'>Rutul<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/tkr' target='_blank'>Tsakhur<\/a><br>","<a href='http://glottolog.org/resource/languoid/iso/ddo' target='_blank'>Tsez<\/a><br>"],null,["Andi","Gagatli","Zilo","Rikvani","Kusur","Bezhta","Botlikh","Genukh","Khlyut","Ikhrek","Kina","Kiche","Rutul","Gel'mets","Kidero"],{"clickable":false,"noHide":true,"direction":"right","opacity":1,"offset":[12,-15],"textsize":"10px","textOnly":true,"style":{"font-size":"14px"},"zoomAnimation":true,"className":""},null]},{"method":"addScaleBar","args":[{"maxWidth":100,"metric":true,"imperial":true,"updateWhenIdle":true,"position":"bottomleft"}]},{"method":"addLegend","args":[{"colors":["#CD8500","#FFFF00","#DB7093","#F4A460","#FFC0CB","#74C476","#ADFF2F","#2E8B57","#FF4040"],"labels":["Andi","Avar","Bezhta","Botlikh","Hinuq","Lezgian","Rutul","Tsakhur","Tsez"],"na_color":null,"na_label":"NA","opacity":1,"position":"topright","type":"factor","title":"Language","extra":null,"layerId":null,"className":"info legend"}]}],"limits":{"lat":[41.496274,42.800361],"lng":[45.9583,47.533824]}},"evals":[],"jsHooks":[]}</script> --- ## Simple counts for Turkic in Rutul Proof of concept: - Ikhrek: 94 loans in at least one speaker, 82 in at least two, 77 in three, 66 in all four - Kina: 93 loans in at least one speaker, 81 in at least two, 62 in all three - Kiche: 81 loans in at least one speaker, 61 in both Results seem to be pretty stable --- ## Simple counts for Turkic in Rutul - Cross-village comparison of loan inventory stability. How many loans only occur in one village? - Ikhrek: 5 loans occur in at least one speaker; 2 in two, 2 in 3, 2 in all 4 - Kina: 3 loans occur in in at least one speaker; 2 in 2; 2 in 3 - Kiche: 6 loans occur in at least one speaker; 2 in both 69 common loans attested in at least one speaker out of each village 54 in at least two speakers out of each village --- ## Simple counts for Turkic in Rutul - Cross-section of inventory sets between the villages Common in: Ikhrek^Kina 30; Kina^Kiche 20; Ikhrek^Kiche 10 Present in Ikhrek+ but absent in Kina- 56; Kina+Ikhrek- 34 Ikhrek+Kiche- 87; Kiche+Ikhrek-99 Kina+Kiche- 47; Kiche+Kina- 87 --- ## Similarity sets One meaning may correspond to one or more lexemes in a language. Each distinct lexeme forms a set - similar lexemes belong to the same set. **SV style** <table> <thead> <tr> <th style="text-align:left;"> meaning </th> <th style="text-align:left;"> Rutul Rutul </th> <th style="text-align:right;"> root </th> <th style="text-align:left;"> Kina Rutul </th> <th style="text-align:right;"> root_1 </th> <th style="text-align:left;"> Khlut Lezgian </th> <th style="text-align:right;"> root_2 </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> the watermelon </td> <td style="text-align:left;"> хъарпуз </td> <td style="text-align:right;"> 1 </td> <td style="text-align:left;"> хъарпыз </td> <td style="text-align:right;"> 1 </td> <td style="text-align:left;"> хъарпуз </td> <td style="text-align:right;"> 1 </td> </tr> <tr> <td style="text-align:left;"> the carrot </td> <td style="text-align:left;"> абадур </td> <td style="text-align:right;"> 1 </td> <td style="text-align:left;"> абадур </td> <td style="text-align:right;"> 1 </td> <td style="text-align:left;"> NA </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:left;"> the carrot </td> <td style="text-align:left;"> NA </td> <td style="text-align:right;"> 0 </td> <td style="text-align:left;"> NA </td> <td style="text-align:right;"> 0 </td> <td style="text-align:left;"> газар </td> <td style="text-align:right;"> 1 </td> </tr> <tr> <td style="text-align:left;"> the broom </td> <td style="text-align:left;"> мугул </td> <td style="text-align:right;"> 1 </td> <td style="text-align:left;"> NA </td> <td style="text-align:right;"> 0 </td> <td style="text-align:left;"> NA </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:left;"> the broom </td> <td style="text-align:left;"> NA </td> <td style="text-align:right;"> 0 </td> <td style="text-align:left;"> хьырыс </td> <td style="text-align:right;"> 1 </td> <td style="text-align:left;"> NA </td> <td style="text-align:right;"> 0 </td> </tr> <tr> <td style="text-align:left;"> the broom </td> <td style="text-align:left;"> NA </td> <td style="text-align:right;"> 0 </td> <td style="text-align:left;"> NA </td> <td style="text-align:right;"> 0 </td> <td style="text-align:left;"> кул </td> <td style="text-align:right;"> 1 </td> </tr> </tbody> </table> --- ## Similarity sets One meaning may correspond to one or more lexemes in a language. Each distinct lexeme forms a set - similar lexemes belong to the same set. **MD style** <table> <thead> <tr> <th style="text-align:left;"> meaning </th> <th style="text-align:left;"> Rutul Rutul </th> <th style="text-align:right;"> root </th> <th style="text-align:left;"> Kina Rutul </th> <th style="text-align:right;"> root_1 </th> <th style="text-align:left;"> Khlut Lezgian </th> <th style="text-align:right;"> root_2 </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> the watermelon </td> <td style="text-align:left;"> хъарпуз </td> <td style="text-align:right;"> 1 </td> <td style="text-align:left;"> хъарпыз </td> <td style="text-align:right;"> 1 </td> <td style="text-align:left;"> хъарпуз </td> <td style="text-align:right;"> 1 </td> </tr> <tr> <td style="text-align:left;"> the carrot </td> <td style="text-align:left;"> абадур </td> <td style="text-align:right;"> 1 </td> <td style="text-align:left;"> абадур </td> <td style="text-align:right;"> 1 </td> <td style="text-align:left;"> газар </td> <td style="text-align:right;"> 2 </td> </tr> <tr> <td style="text-align:left;"> the broom </td> <td style="text-align:left;"> мугул </td> <td style="text-align:right;"> 1 </td> <td style="text-align:left;"> хьырыс </td> <td style="text-align:right;"> 2 </td> <td style="text-align:left;"> кул </td> <td style="text-align:right;"> 3 </td> </tr> </tbody> </table> --- ## From similarity sets to distance matrices - Convert shared loans into similarity models (neighbornet): Number of times two languages share a similarity set is converted into a distance matrix - Simplistic method: Count similarities between lects by counting how many similarity sets two lects share. - Issue: similarities by cognate are counted (to be excluded?). - Issue: NOT having the same loan is counted as similarity, even if different items are used (Are 0's indeed counted?) - Complification: A similarity sets is only counted if it goes beyond a set of closely related languages. Lines where similarity sets are contained in e.g. Turkic only or Rutul only are excluded from the counts. (MD-style below) - Complification: One meaning is counted twice. Two languages are deemed similar within a meaning if the share at least one similarity set for this meaning. --- ## Similarity to distance matrix - The number of times two languages share a similarity set is converted into a distance matrix - Distance - number of shared sets divided by the number of meanings (minus the meanings for which one of the lects had not data) -- - Distance matrix forms the input for a neighbournet visualization -- <table> <thead> <tr> <th style="text-align:left;"> </th> <th style="text-align:right;"> DAzer </th> <th style="text-align:right;"> DKumyk </th> <th style="text-align:right;"> DLezgian </th> </tr> </thead> <tbody> <tr> <td style="text-align:left;"> DAzer </td> <td style="text-align:right;"> 0.0000000 </td> <td style="text-align:right;"> 0.6134454 </td> <td style="text-align:right;"> 0.7435897 </td> </tr> <tr> <td style="text-align:left;"> DKumyk </td> <td style="text-align:right;"> 0.6134454 </td> <td style="text-align:right;"> 0.0000000 </td> <td style="text-align:right;"> 0.7478992 </td> </tr> <tr> <td style="text-align:left;"> DLezgian </td> <td style="text-align:right;"> 0.7435897 </td> <td style="text-align:right;"> 0.7478992 </td> <td style="text-align:right;"> 0.0000000 </td> </tr> <tr> <td style="text-align:left;"> DRutul </td> <td style="text-align:right;"> 0.6971154 </td> <td style="text-align:right;"> 0.7089202 </td> <td style="text-align:right;"> 0.6509434 </td> </tr> </tbody> </table> --- class: inverse, center, middle ## Rutul area --- ## Rutul area (SV style) 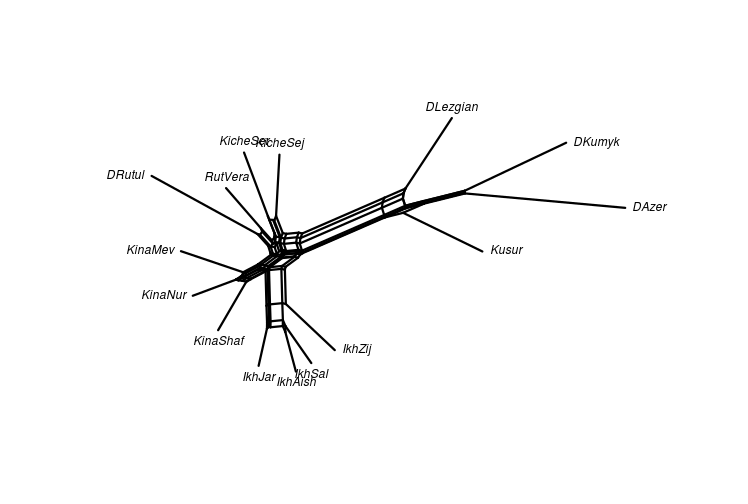<!-- --> --- ## Rutul area (MD style) 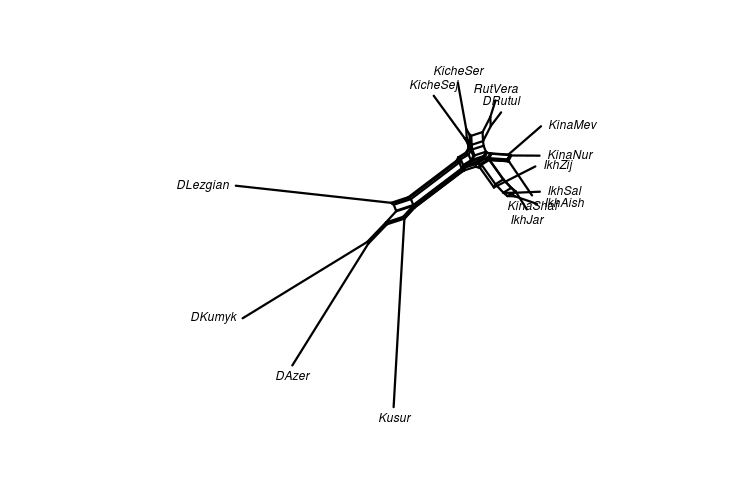<!-- --> --- class: inverse, center, middle ## Without "stop words" If a meaning has a different lexeme in each language, remove it. The idea is to measure distance based on loans only. --- ## Rutul area (SV style) 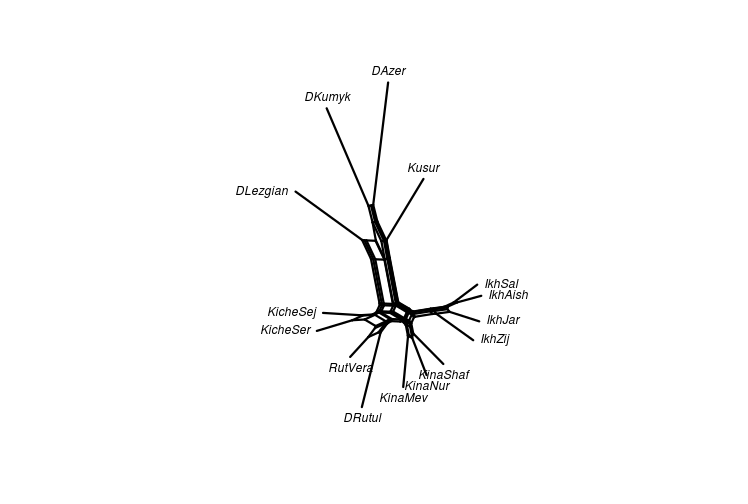<!-- --> --- ## Rutul area (MD style) 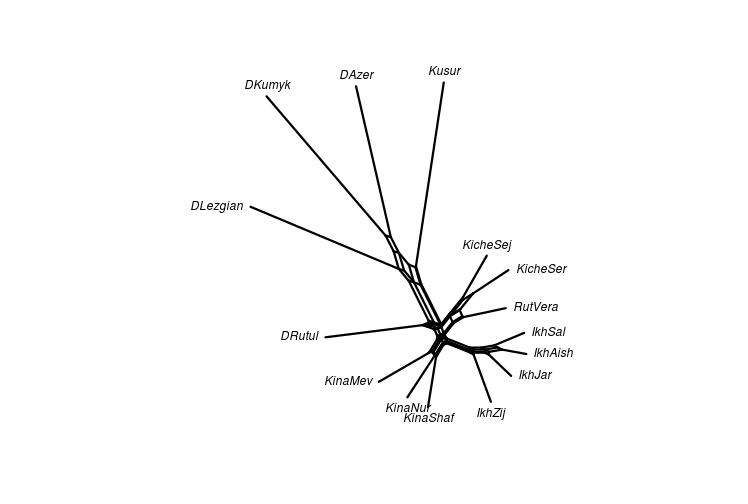<!-- --> --- class: inverse, center, middle ## Distance between major languages Based on a larger subset of the WOLD questionnaire (~600 items). Data gathered from dictionaries. Visualizations based on the same variables as the Rutul data. --- ## Major languages (SV style) <!-- --> --- ## Major languages (MD style) <!-- --> --- class: inverse, center, middle ## Without "stop words" If a meaning has a different lexeme in each language, remove it. The idea is to measure distance based on loans only. --- ## Major languages (SV style) <!-- --> --- ## Major languages (MD style) <!-- --> --- class: inverse, center, middle ## Avar area --- ## Avar area (MD style) 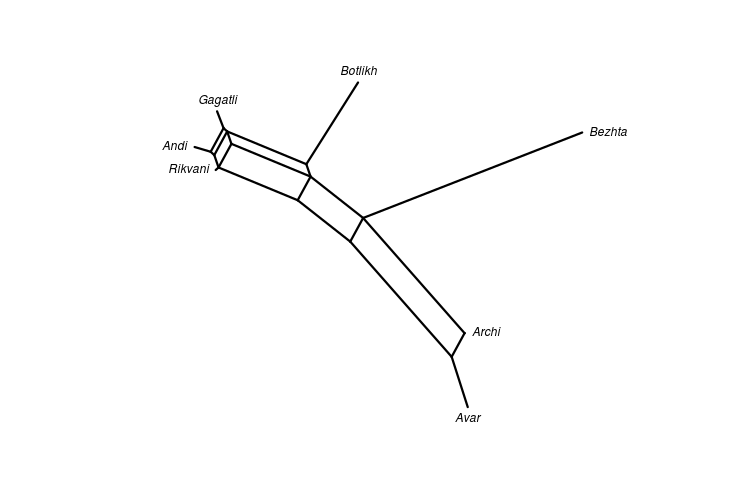<!-- --> Only one Avar word common to all: *ʁalbac'* 'lion'. --- ## Further plans - Converge the Rutul and the Andi branches of the project -- - Focus on one type of data analysis / visualization -- - Learn more about neighbornets --- ## Thank you! We used [**lingtypology**](https://ropensci.github.io/lingtypology/), [**phangorn**](https://cran.r-project.org/web/packages/phangorn/index.html) and [**xaringan**](https://github.com/yihui/xaringan) for this presentation.